Machine Learning
Summary
Reddit is a large online community with different opinions on different topics. From using NLP techniques, we have extracted a suite of topic and sentiment features, and subset language-specific reddit posts. Now, to use the data for specific task, we are able to use bag-of-words features to predict Ukrainian reddit scores with a 95% accuracy.

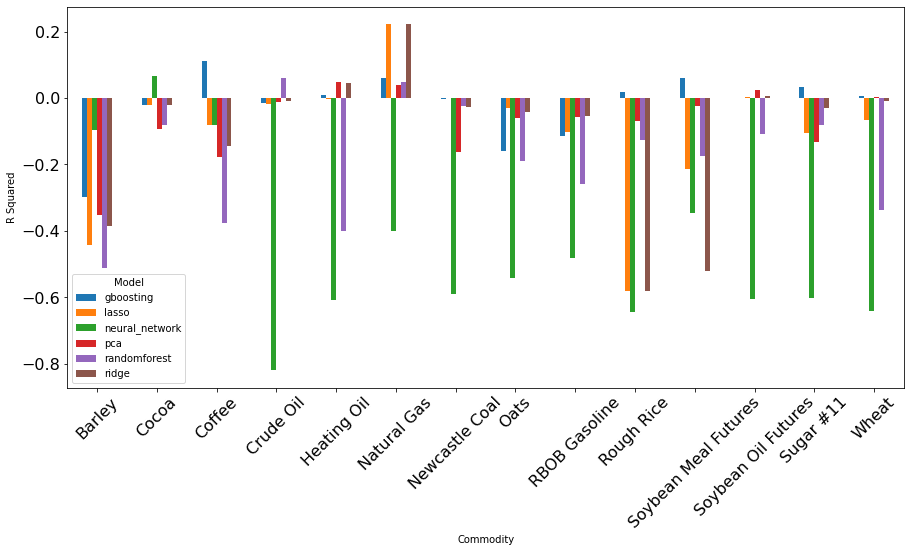
FIGURE 1 (left)Model Performance from
Comment Features. (right)Model Performance from Comment Features on each commodity.
Visualization
Code
As our primary goal, we also predict commodity returns with sentiment and topic features. Financial asset returns are notoriously hard to predict. A positive R^2 in modeling means a better-than-guess prediction, and if the positive R^2 stays long enough, it can be built into a trading signal. As Figure 1 shows, even though most of our models can only generate negative R^2, we can make a positive R^2 prediction using Gradient Boosting. This result is two-fold. On the one hand, reddit data has a low information-to-noise ratio for it to be used in commodity returns prediction. On the other hand, it shows potential to generate decent prediction with optimal features and advanced modeling. The most remarkable result is for commodity like Natural Gas, Reddit shows strong predictive power with almost any models.
Q5. Can Foreign Language Comments be used to Predict Comment Score? Using Transformation, Pipeline, and SparkML.
We split the training and testing dataset by 0.7 and 0.3 ratio from Ukrainian comment dataset, with 12859 and 5462 posts respectively. We utilize SparkML and Spark Pipeline to streamline the tokenize, word vectorization, and machine learning process. Logistic regression has the best performance with a 95.75 Accuracy. We conclude that bag-of-words approach text classification methods can be applied to any language that uses space to separate words and perform well. The code can be found here.
Q7, Q9, & Q10. How to use Reddit Topics and Sentiments to Predict Commodity Returns?
Models
Gradient Boosting
Boosting refers to modifying a weak learner or a weak hypothesis to make it perform better. A weak hypothesis or a weak learner is defined as one whose performance is at least slightly better than a random chance.
In gradient boosting, decision trees are used as the weak learner and are parameterized using gradient descent. Each tree obtains the instances it handles well and leaves the hard-to-handle instances to the following trees. The model adds a fixed number of tree-structured weak learners once a time and stops when the loss reaches an acceptable level or no longer improves on external validation data. Thus, gradient boosting is a greedy algorithm that can quickly overfit a training dataset. We tune several key hyperparameters to add constraints to the training process.
- learning_rate: The model shrinks the contribution of each tree by the specified learning rate. default is 0.1
- n_estimators: The number of boosting stages to perform. More boosting stages add more trees to the model and perform fairly better. There is a considered trade-off between learning_rate and n_estimators, but we give a fair amount of attempts for both parameters in the hope of the best performance.
- max_depth: The maximum depth limit the number of nodes in the tree. And it can start with one node per tree.
- subsample: The value determines the fraction of samples to be used from fitting individual base learners.
We first set up lists of these parameters in their acceptable range with large intervals. After looping through all combinations, we obtain the best set of parameters. We then derive new lists around the result with smaller intervals. Using this method, we get close to the actual range of possible best estimators. Although the models using different combinations are obtained through training and validation datasets, we filter the estimators with the highest r-squared score from the prediction on the test dataset to avoid overfitting.
Random Forest Regressor
Random Forest is another ensemble method that enhances learning by grouping weak learners to form a single strong learner. The robustness of Random Forest comes from the wisdom of crowds and works well on large datasets. Also, decision trees are good at capturing non-linear relationships between input features and the target variable.
We use Random Forest Regressor model to predict commodity returns. Similar to Boosting, the parameters tuned in the model are n_estimators and max_depth. Then we set up lists of these parameters and loop through all combinations to get the best set of parameters. Finally, we filter out the estimators with the highest r-squared score.
- n_estimators: the number of trees in the forest
- max_depth: The maximum depth limit the number of nodes in the tree
Feedforward Neural Network
Feedforward Neural Network is a group of models using linear layers and activation. It could be used to model non-linear relationships and dig into the deep insights of a dataset. Gradient descent based optimizers and schedulers are used for the training process. Neural Network is different from the previous two methods. It requires a large number of choices for training hyper-parameters.
To avoid overfitting, we maintain 2 hidden layers for the network, with the units of the 2nd hidden layer being 2 times the units of the 1st hidden layer.
We use an Adam optimizer, a linear scheduler with warmups and, the MSE loss function for the optimization program.
We first try to find the best choice of hyper-parameters according to r-squared scores, by training the model on the training dataset and then do validation on the validation dataset. With the best choice of hyper-parameters, we do formal training on the overall training dataset and get the r-squared scores on the testing dataset.
- base_hidden_layer_units: The base number of units for the first hidden layer.
- learning_rate: The variable deciding the scale of gradient changes applied to network parameters.
- epochs: The time of optimization processes on the training dataset repeatedly.
- activation: The choice of activation function for hidden layers.
- batch_size: Size of batch to compute the loss. Updating parameters using the loss computed on a batch of data points prevents the network from going into some local optimal regions.
- max_grad_norm: The value used to clip the parameter gradients before each update.
- num_warmup_steps: Warmup steps for the scheduler. Default 3.
All the models' code can be found here.
Results

FIGURE 2 Performance of Different ML
Models. The left figure plots the performance using comment-generated features. The right figure plots the
performance using submission-generated features.
Visualization
Code
Because the market is very efficient, financial asset returns are hard to predict. From FIGURE 2, even though most models do not work well, gradient boosting can generate positive returns. Moreover, we notice that comment-generated features generally have better results than submission-generated features.
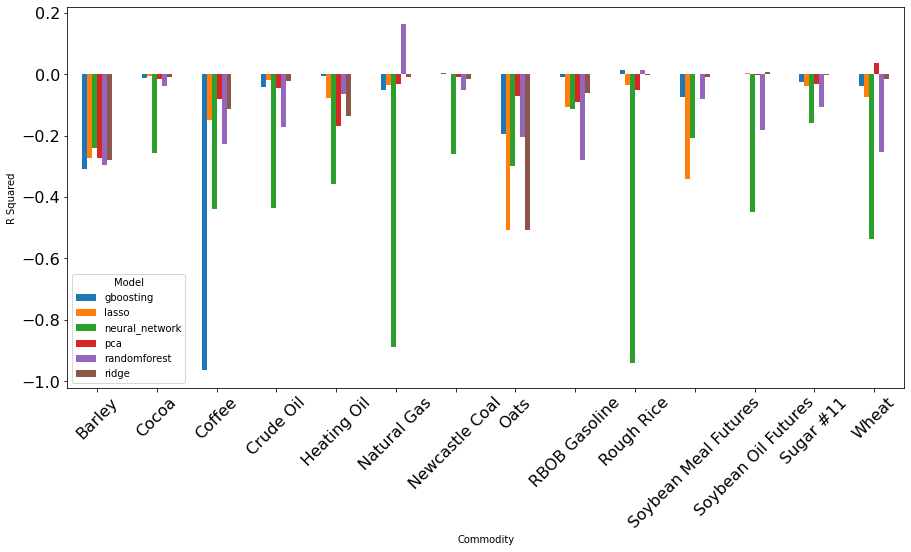
FIGURE 3 Performance of Different ML
Models on Different Commodities. The left figure plots the performance using comment-generated features.
The right figure plots the
performance using submission-generated features.
Visualization
Code
FIGURE 3 plots the model performance on each asset. It is clear to see that some assets can be better predicted than others. Predictions on Natural Gas returns are almost always better than other commodities.
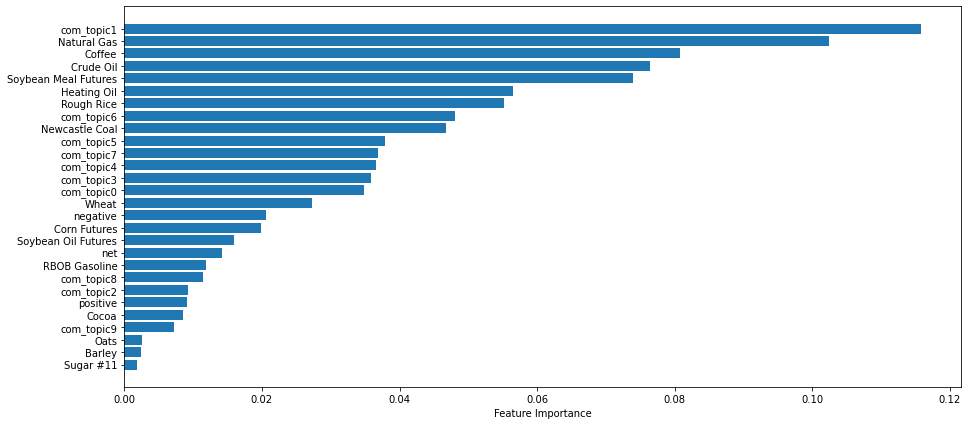
FIGURE 4 Feature Importance on Natural Gas Prediction.Visualization Code.
FIGURE 4 plots the feature importance of gradient boosting method on natural gas prediction. The first topic related to [people, city, vote, crimea, putin, territory, state, country, force, belarus] has the best predictive power. Topic timeseries and other commodity features also show strong importance in gradient boosting method.