Conclusion
The Russian and Ukraine conflict has sparked global financial market turmoil. Although people have already learned how vulnerable the stock market is to such events from COVID, the conflict between two of the world's biggest exporters takes its turn and shades the shadow over the commodity market. Learning how the market reacts to such events becomes crucial. We want to interpret the association between the commodity market and the conflict through other medians. We use the information extracted from Reddit for this project. The messages behind the text from such an open online forum are compelling. The hidden sentiments people produce and perceive, as well as the underlying topics generated by the discussion, can all reflect opinions about the conflict. In this project, we extract such information from Reddit content and use them as measurements of the conflict. We then build models to predict the commodity market performance with these measurements. With our result, we can make the market more resilient to shocks like this.
A subreddit is a specific community in the social media website Reddit and it is dedicated to a specific topic that people write about. We use it to filter out the contents from the original Reddit dataset, which contains every posts and comments from January 2021 to August 2022.
We replicate the date collection process from A Reddit Dataset for the Russo-Ukrainian Conflict in 2022. The resulting subset from the original dataset shows that the submissions are more active after the declaration of Russia-Ukraine conflict at the end of February.

FIGURE 1:Starting from February 2022, number of posts in the dataset increased drastically when the Russia-Ukraine conflict became a global issue.Visualization Code.
We collect commodity prices of Barly, Cocoa, Coffee, Corn, Crude Oil, etc. from investing.com as our external data and target variable that we aim to predict using Reddit data.
While the Reddit dataset contains different types of data, the most important information remains in the text. We place our primary focus on sentiment analysis and topic modeling. Sentiment analysis generates the daily average sentiment scores, and topic modeling extracts the essential topics and assigns the daily topic proportions.
We use "analyze_sentimentdl_use_twitter", a machine learning approach sentiment pipeline from John Snow Labs, to assign sentiment scores to each post. Figure 2 plots the daily sentiment scores as well as the 10-day moving-average for both the submission and comment datasets.
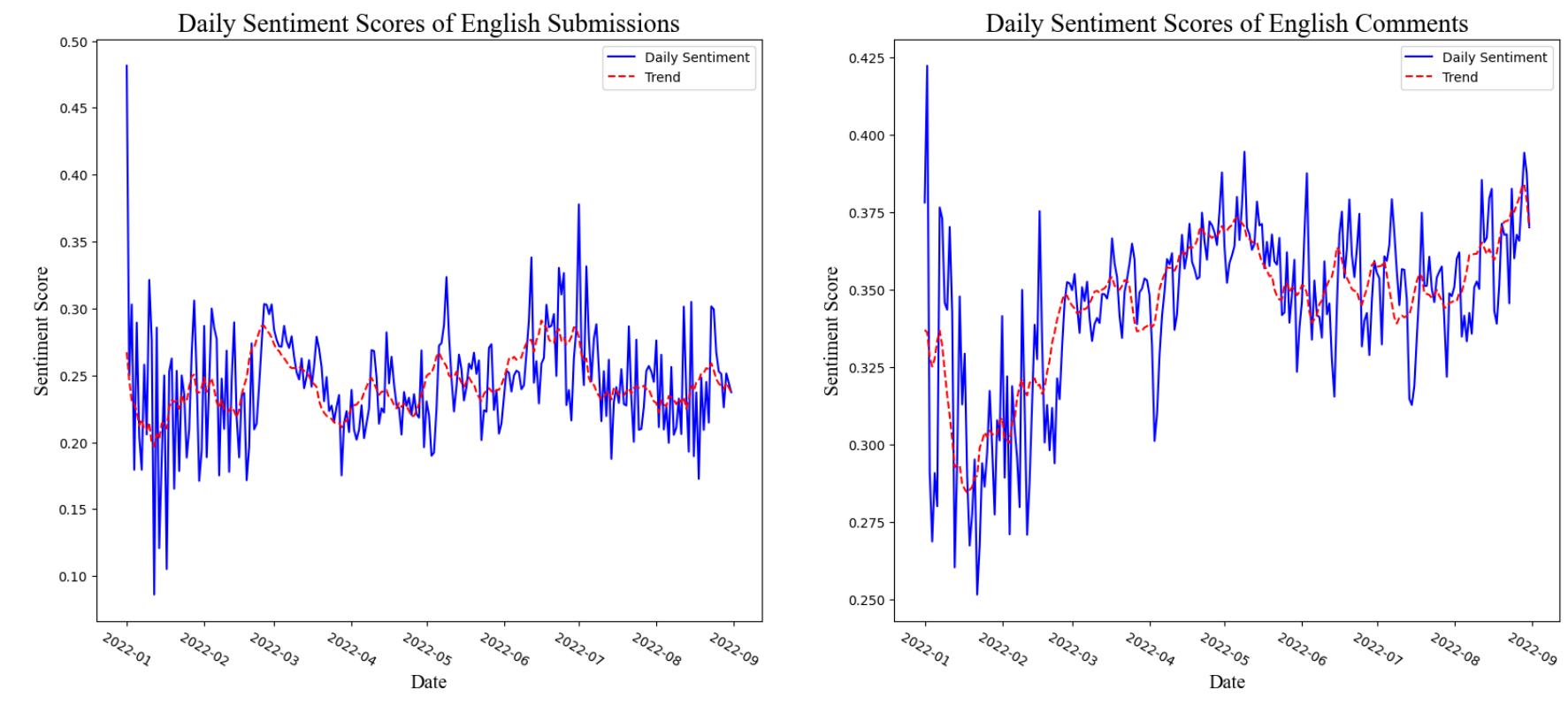
FIGURE 2 Sentiment Score Time Series. Trend is the 10-day moving average.Visualization Code.
We construct 10 topics using LDA for both the submission and comment datasets. Figure 3 plots the daily topic proportions as timeseries.

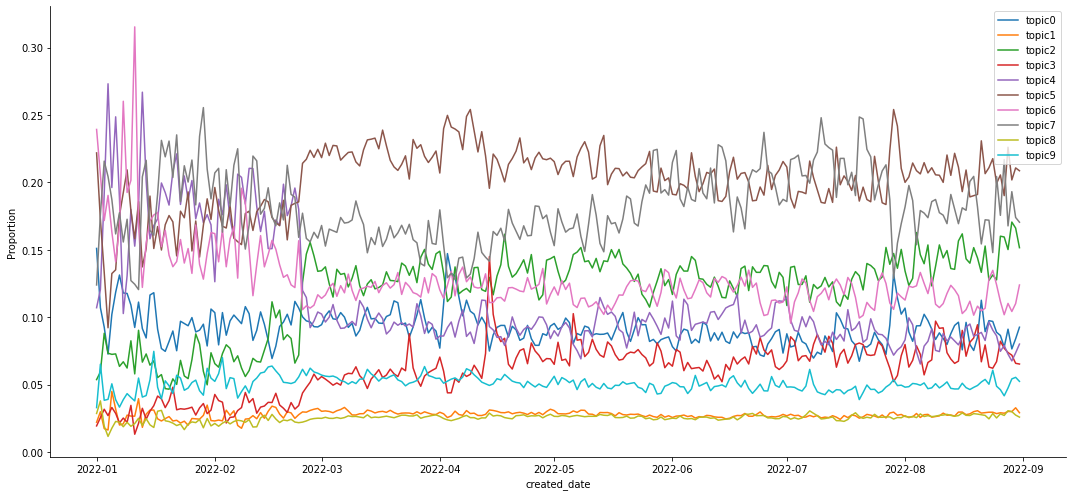
FIGURE 3 Time-series plot of topics
proportion in the Reddit submissions (top) and comments (bottom)
LDA
time-series code.
Sentiment and topic are two major components of text data. Sentiment focuses on Redditor's feelings and subjective experience, while topic focuses on facts and objective information. We build models with the generated sentiment and topic features to predict daily commodity returns from the external dataset.
Our training set is the commodity returns from February 23rd to June 30th; validation set is from July 1st to July 31st; and our test set is from August 1st to August 31st. We experiment 6 machine learning models to minimize Mean Squared Error(MSE), including Lasso/Ridge Regression, Principal Component Regression, Random Forest, Gradient Boosting, and Neural Network.
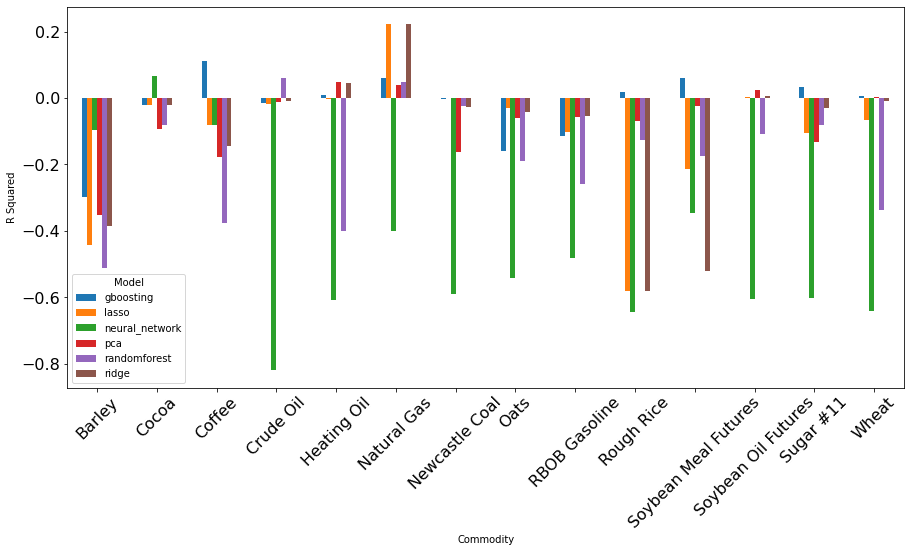
FIGURE 4 Model performance with comment-generated features.Visualization Code.
Predicting returns is a difficult task. FIGURE 4 plots the performance of models on different commodities. Among the models, Gradient Boosting method has the best average Out-Of-Sample R^2. And Natural Gas is much better predicted than the other commodities, showing positive R^2 for all the models except Neural Network.
Next Steps
Our analysis includes 1-day lag commodity returns in our feature set, which is equivalent to an AR(1) model. Since the commodity market can have spillover effects lasting more than one day, it can be helpful to include more orders in our prediction models. Moreover, Vector Autoregression(VAR) can further explore the inter-dependence between the Reddit community and the financial market.
From correlation analysis, machine learning algorithms, and AR model, we make associational claims about the feature set and the target variables. A caveat of this reasoning is that the relationship can be coincidental or non-causal. To make the project more rigorous, a next step for us is studying the causal effect between Russia-Ukraine related Reddit posts and commodity returns.