Natural Language Processing
Summary
We construct sentiment and topic features from the Reddit posts, to reflect what people talk about and how they feel about the Russia-Ukraine Conflict event. From the topic modeling, we find the submissions are concentrated among major three topics about “military force”, “city riot”, and “sanctions”, while the comments are more balanced on different topics. From the sentiment analysis, as Table 1 shows, we find people have more negative comments and submissions than the positive ones, and they also tend to give higher scores for negative posts. From our preliminary analysis, we do not find strong correlations between commodity returns and topics or sentiments. This is not unexpected due to returns notoriously have low signal-to-noise ratios, and it also suggests that we should have more flexible model to capture text information.
| Score Stats | Counts | Average | Range | IQR | Std | Skewness |
| Positive Submissions | 66445 | 296.23 | 0~108426 | 109 | 1741.93 | 22.05 |
| Negative Submissions | 192527 | 313.31 | 0~195763 | 168 | 1554.17 | 29.21 |
| Positive Comments | 2375428 | 9.51 | -618~8607 | 5 | 47.40 | 33.37 |
| Negative Comments | 4144561 | 10.87 | -657~9421 | 6 | 52.92 | 33.31 |
TABLE 1 Statistics of Sentiment Scores. Visualization Code.
Data Cleaning
Our text data sets are the Reddit comments and submissions from January 1, 2022 to August 31, 2022, amounting to 10,378,762 unique posts. For submission posts, "title" and "selftext" are concatenated. We leverage Apache Spark and Spark NLP to build the text processing pipeline. Figure 1 plots our data processing flow. First, we used the pre-trained model “detect_language_375” provided by John Snow Labs, to detect the languages of each post and estimate the language proportion from 0 to 1. We include posts in Ukrainian, Russian, and English, and create three sub-datasets for each of them by selecting posts with an estimated proportion above 0.8 for that language. Secondly, we remove posts with “[removed]”, “[deleted]”, and “[deleted by user]”. Thirdly, we apply common natural language text cleaning procedures including 1) changing all words into lower case, lowercase; 2) removing numbers, punctuations,and stopwords; 3) lemmatizing each word to its single format, e.g. "words" to "word", "makes" to "make".
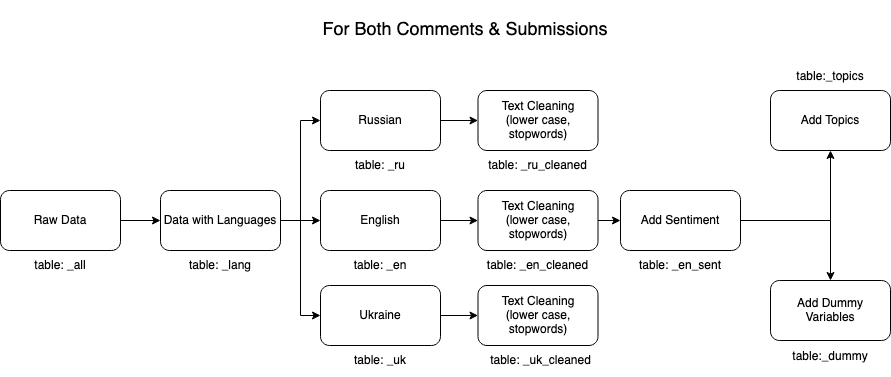
FIGURE 1 Data Pipeline. Pipeline Code.
We collect the commodity futures' price data from investing.com. The data has the same date range as the Reddit data from January 1, 2022 to August 31, 2022, covering 15 major food and energy commodities. To calculate the returns, we use daily close-to-close prices.
Q1. (NLP) What are the major topics discussed in Reddit related to Russia Ukraine conflict?
Topic models generate interpretable text features extracted from documents. These models help identify and cluster similar documents and are useful tools to tag documents.
Spark MLlib documentation specifies the terminology used in this analysis: Link
- term = word: an element of the vocabulary
- token: instance of a term appearing in a document
- topic:multinomial distribution over terms representing some concept
- document: one piece of text, corresponding to one row in the input data
Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) is a statistical model that helps produce meaningful topics that humans can relate to. It assumes that topics are probability distributions over words, and documents are distributions over topics and that topics use only a limited number of terms frequently.
- k: number of topics (= number of clusters)
- maxIter: number of iterations
- featuresCol: a collection of documents as input data. Feature transformers such as Tokenizer and CountVectorizer are used to convert text to word count vectors as input data.
Topic Modeling Pipeline
We proceed with 15 topics, top 10 words per topic using the cleaned documents as input data. The notebook contains the LDA pipeline applied to the submissions and comments data. The data from two sources are stacked using union command to provide comprehensive topic modeling on every posts related to RU Conflict in the Reddit dataset.

FIGURE 2 LDA Pipeline
The DocumentAssembler transforms the input data to annotation format so that Spark can use it as input data - DOCUMENT. The Tokenizer splits lines in document into words - TOKEN. Finally, the Finisher transforms the annotation format of Spark NLP to a "human-readable" format. Normalizer (lowercasing), Lemmatizer, and StopWordsCleaners are skipped in this pipeline since they are already processed in the Data Cleaning step. The CountVectorizer is used to count the frequency of the each term in the document and provide input data for the LDA model. (featuresCol vector)
Reference: Topic Modelling with PySpark and Spark NLP - Maria obedkova
The table below summarizes the result 15 topics and top 10 words per each topic.
| Topic # | Topic Words - Submissions | Topic Words - Comments |
|---|---|---|
| 1 | [tank, force, kharkiv, movie, military, fire, farmer, soldier, kherson, destroy] | [people, city, vote, crimea, putin, territory, state, country, force, belarus] |
| 2 | [day, mariupol, crime, putin, soldier, obama, invasion, military, drone, news] | [fuck, shit, love, hell, lol, lmao, think, fake, guy, holy] |
| 3 | [force, putin, people, soldier, military, fight, kyiv, video, destroy, make] | [call, word, true, point, good, haha, game, putin, speak, man] |
| 4 | [city, shirt, force, riot, card, military, fest, chinese, mariupol, people] | [people, soldier, kill, good, die, man, fight, hope, putin, dead] |
| 5 | [army, musk, elon, destroy, starlink, gas, gazprom, anonymous, putin, church] | [orc, meme, low, effort, high, sunflower, send, supportive, opinion, seed] |
| 6 | [putin, discord, kyiv, people, flag, tank, aid, fighter, bomb, poland] | [mod, rule, information, message, reddit, issue, vital, remove, mail, muted] |
| 7 | [nance, people, malcolm, day, invasion, conspiracy, side, mother, talk, president] | [post, video, comment, source, make, read, link, news, bot, question] |
| 8 | [denazification, nazi, nazism, content, support, make, putin, moderator, reddit, military] | [people, make, putin, country, time, nato, military, world, thing, year] |
| 9 | [putin, president, zelensky, nuclear, plant, bayraktar, island, indian, win, power] | [special, operation, translation, putin, dick, awesome, pretty, ah, start, suck] |
| 10 | [company, support, business, suspend, sanction, bank, military, stop, putin, asset] | [missile, air, system, drone, china, fly, ship, target, time, fire] |
TABLE 2 Top 10 topic words processed for 10
Topics
Topic
Modeling code (submissions)
Topic
Modeling code (comments)
Topic modeling is a popular technique to analyze the massice amount of textual social media data. It is a efficient tool to summarizing long documents. Some of the findings through the topic modeling includes:
- Words related to the war: The subreddit names used to subset the data included not only the war-specific keywords. However, we can see that topic words related to the 'war' such as military, soldier, and tank, dominates the topic modeling result.
- Geographical information: Geographical names such as Kyiv (Capital of Ukraine), Mariupol indicates where the war broke out and the country names such as China, Belarus and Poland tell us countries near Russia and Ukraine that were affected by the war.
- Others: We can find topics that people talk about such as the war strategies Russia takes. Starlink, gas, nuclear plant, power indicates that people are interested in Russia's attack on the major infrastructures in Ukraine.
Topics found from the LDA model can be later used to label the documents. Figure 3 shows the change of topics of more interest in Reddit over time. The figures are drawn by first tagging the documents using the topic words and then calculating daily proportions. This shows that the topic model can be used transform the textual analysis to classification problems.

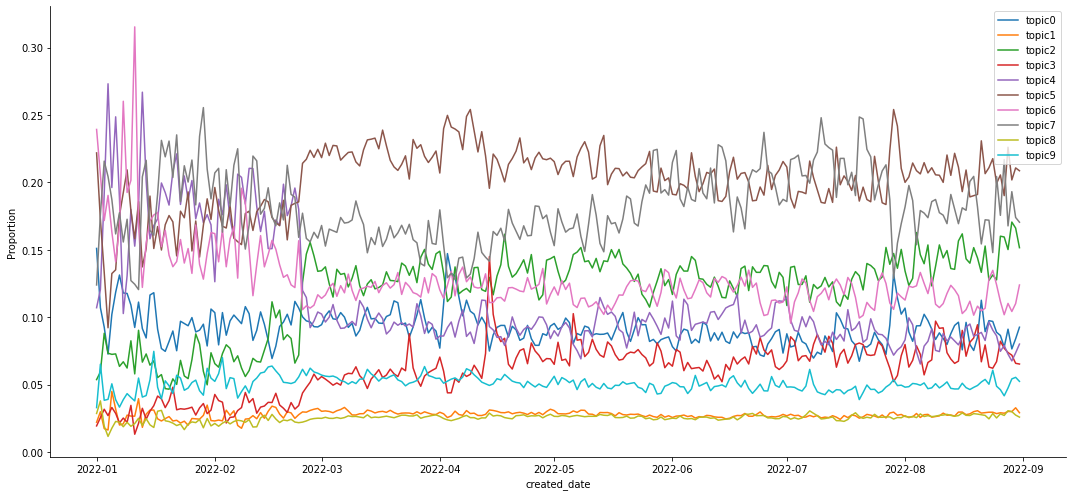
FIGURE 3 Time-series plot of topics
proportion in the Reddit submissions (top) and comments (bottom)
LDA
time-series code
Q2. (NLP) What are different languages other than English that can be analyzed in the Dataset? (language detection)
Although it is easy to assume that most of the Reddit content is in English, based on the chosen topics, we target English, Ukrainian, and Russian as the languages of interest. To categorize the submission records by language, we use Spark NLP pre-trained language detection model detect_language_375. We obtain the prediction confidence toward these three languages for each submission and comment content. With the confidence values, we can define dummy variables for three languages by any desired bar. For the NLP part of our project, we subset our data by their language with 80% confidence. Figure 5 shows how the volumes of submissions in different languages change over time. We conduct our common word analysis using PySpark SQL functions, following the process of tokenizing, aggregating by vocabulary, counting, and sorting. We obtain the TF-IDF scores for our vocabularies using PySpark machine learning feature algorithms. The extraction and transformation tools include Tokenizer, HashingTF, IDF. We map the resulting TF-IDF score to words by user-defined functions under the PySpark SQL environment. Since we are dealing with foreign languages, we also utilize Spark NLP pre-trained pipeline translate_ru_en and translate_uk_en, enabling translation from Russian and Ukrainian to English, respectively. When we only need the translation for word tokens, we use the pipelines start with document assembler, followed by the Spark Neural Machine Translation framework Marian models opus_mt_ru_en and opus_mt_uk_en respectively. The results we obtain give us insights into how the focus of the discussion in different languages varies from each other. However, since there is a significant gap between the volume of records in English and the volume of records in Russian and Ukrainian, we will not include records in these languages in our further explorations.

FIGURE 4 Volumes of submissions in English, Ukrainian, and Russian over the observation period.Visualization Code.
Q3. Which topics/kinds of submissions/comments are more popular?
Applying the TF-IDF method to our text data gives us more insight into online discussions. With the pyspark machine learning features and annotators, we feed our cleaned text data through the tokenizer. And then conduct hashing term frequency transformation for the tokenized column. HashingTF enables dimensionality reduction to the dataset, which is very helpful when working on large-sized data in a distributive manner. We then compute the inversed document frequency for each TF vector corresponding to the text records. By extracting function properties and annotator returns, we map the TF-IDF score back to the textual word tokens and sort them to find the most important words. Please refer to this notebook for calculating the TF-IDF scores.
TF-IDF stands for term frequency-inverse document frequency. It is a statistical measure that evaluates how relevant a words is to a document in a collection of document.
The TF term frequency measures how many times one instance of word appears in the a document over the length of the document. In our case, how many time one word token appears in one comment/submission text body over the length of the comment/submission.
\(TF = \frac{count\ of\ the\ word\ in\ document}{number\ of\ words\ in\ document}\)
The IDF inverse document frequency measures how common or rare one instance of word is in the entire document set. In our case, how common or rare a word token is over the whold subsets of comments or submissions texts. The small the IDF is the more common a word is. The IDF essentailly help us eliminate the interference of words like Ukrainian and Russian when trying to extract important words.
\(IDF (inversed\ document\ frequency) = \log \frac{total\ number\ of\ documents}{number\ of\ documents\ containing\ the\ word}\)
The TF-IDF score is calculated for every unique word token appears in the text body of our dataset. The higher the score is, the more critical the word is.
\(TF-IDF =\ TF \times IDF\)
TF-IDF helps us discard the dominance of words like country names and wars. The critical words give us different perspectives of the discussion. The word children appeares as one of the most important word in Russian submissions, shows us that peopel are paying attention to the future generation during a hard time. We can also see political or geometrical representations like European, German, and Belarus. Words like brigade, combat, and front imply more detailed descriptions and discussion going on in the military-related discussion. The nickname "Dr. Eisenfaust." for the Mayer of Kyiv brings up a new political figure other than Putin. Instead of nouns, more adjectives appearing as important words bring out the discussion nature of Reddit.
| Language | Reddit Subset | Top 10 common words by word counts | Top 10 important words by TF-IDF |
|---|---|---|---|
| English | submission | ukraine, russian, russia, ukrainian, war, putin, people, forces, military, russians | european, german, full, man, belarus, combat, avoided, left, brigade, front |
| comment | russia, ukraine, russian, war, people, putin, russians, ukrainian, time, good | hypercompetence, yourse, irepepctive, feeeeeeeelings, favorably, eisenfaust, cowy, trackers, correctlynused, isayevich | |
| Russian | submission | это(This is), украины(Ukraine), россии(Russia), украине(Ukraine), рф(Russia), войны(War), просто(simply), против(against), видео(video), очень(Very much) | других(Other), работает(It's working), свои(Their), такие(such), города(City), день(day), помощи(Help), вся(all), детей(Children), лишь(only) |
| comment | это(This is), просто(simply), всё(all), россии(Russia), украине(Ukraine), очень(Very much), которые(That), украины(Ukraine), люди(people), лет(Years) | начали(Started), своим(Your), ситуации(Situation), россияне(Russians), хочет(Wants), самом(The), шмольцы(Schmoltsy), человека(Person), должен(must), страна(country) | |
| Ukrainian | submission | України(Ukraine), Україні(Ukraine), Україна(Ukraine), Україну(Ukraine), Росії(Russia), війни(War), РФ(RF), США(United States), Росія(Russia), the(that) | російська(Russian), військові(Military), останнім(Last), дорослих(Adults), дорозі(Road), думкою(Opinion), олександра(Alexander), дізнатися(find out), my(Mi), дія(action) |
| comment | України(Ukraine), Україні(Ukraine), людей(People), має(Has), війни(War), взагалі(generally), Україну(Ukraine), Україна(Ukraine), питання(question), робити(do) | повномасштабному(large-scale), мови(Language), маю(Mean), наприклад(For example), гроші(money), замінив(Replaced), якісна(Quality), мова(language), українців(Ukrainians), робити(do) |
TABLE 3 Common/Important words found from applying tf-idf. Common Words Code and TF-IDF Code.
As we tagged all the submissions and comments by their languages, we split the datasets into English, Russian, and Ukrainian since they are part of the focus of our textual analysis.
Common words can help us find what has frequently been brought up by people when making comments and posts under our selected subreddits. Inside the spark environment, we explode the body of the comments and submissions into single words. By aggregating all the vocabularies by their counts, we are able to sort them to find the most common words over our time interval of interest. Please refer to this notebook for the code extracting common words.
For the comments and submissions in English, terms related to war appear naturally. The top few are the cognate words of countries, which come with the territory of the subreddits we selected. While we may also interpret part of the counts for russian and ukrainian as referring to the people. Combined with the fact that the word people is one of the most common words, we can find the humane and compassionate nature of the discussion. Moreover, among all the political leaders involved in the conflict, Putin gets most of the attention.
Beyond the top ten words we listed, NATO and the US are the two other political entities that appear the most in the discussion. We also find curse words appear in high frequency, implying an extremely sentimental tone among the posts.
Except the top ten we listed, the common words for posts in Russian and Ukrainian also include words like US dollars and populations, which could suggest different angles of discussions like finance and geopolitics. Words like Green and Babchenko possibly represent political entries and figures that are not familiar to foreign people outside of the confliction area. While again, we can find words that describe peace and human beings.
Q4. How is the sentiment in Reddit posts over time related to Russian-Ukrainian Conflict?
Sentiment analysis casts a view on how people react to the topic of RU conflict. By applying the sentiment analysis pipeline and further processing, we obtain the sentiment scores for each reddit for both submissions and comments.
Creation of Sentiment-Related Attributes & Stats:
- We use the pre-trained pipeline of analyze_sentimentdl_use_twitter provided by John Snow Labs, since that's the most suitable medium-size pipeline for our Reddit case. The language model in this pipeline is a large neural network using encoded embeddings as inputs and trained on the Sentiment140 dataset in a distributed way, which is composed of 1.6 million tweets.
- While this pipeline outputs four kinds of sentiment results: 'positive', 'negative', 'neutral', and 'None', we create a new 'sentiment_score' column, which is 1.0 when positive and 0.0 otherwise, to put an emphasize on the positive sentiments.
- Then we aggregate the average sentiment scores as well as the numbers of positive and negative reddits into daily timeseries. Please refer to these notebooks for the code we use for generating the sentiment-related attributes & statistics.
Table 4 shows a summary of the generated sentiment scores.
| Sentiment Score Stats | Average | Minimum | Maximum | Std | Q1 | Q3 |
| Submissions | 0.244 | 0.086 | 0.481 | 0.041 | 0.220 | 0.268 |
| Comments | 0.344 | 0.251 | 0.422 | 0.028 | 0.334 | 0.362 |
TABLE 4 Statistics of Sentiment Scores. Visualization Code.
From Table 4, we can see that:
- The dates for maximum/minimum sentiment scores in Submissions and Comments are similar.
- Submission scores have larger fluctuations and lower sentiment scores overall than comments.
Each Reddit post also has a score for itself. The score is simply the number of upvotes minus the number of downvotes.Table 5 shows a summary of Reddit scores.
| Score Stats | Counts | Average | Range | IQR | Std | Skewness |
| Positive Submissions | 66445 | 296.23 | 0~108426 | 109 | 1741.93 | 22.05 |
| Negative Submissions | 192527 | 313.31 | 0~195763 | 168 | 1554.17 | 29.21 |
| Positive Comments | 2375428 | 9.51 | -618~8607 | 5 | 47.40 | 33.37 |
| Negative Comments | 4144561 | 10.87 | -657~9421 | 6 | 52.92 | 33.31 |
TABLE 5 Statistics of Scores in Positive/Negative Sentiments. Visualization Code.
From the score summary table, we can see that reddits with negative sentiment tend to have higher Reddit scores. To verify this numerical hypothesis using two-sample t-tests:
- Two-sample t-test for submission scores in 2 sentiments:
- Two-sample t-test for comment scores in 2 sentiments:
statistic = -2.36
pvalue = 0.0179
statistic = -32.64
pvalue = 1.012e-233
The results lead to our conclusion:
Reddits with positive sentiments tend to have lower scores than those with negative sentiments, for both submissions and comments.
We also created two keyword generated dummy variables to separate Reddit posts with Russia-related content such as "Putin", "Russia", etc, from Ukraine-related content such as "Zelensky", "Ukraine", etc. From Table 6, we find that Ukraine-related content has more positive sentiment posts and less negative sentiment posts as compared to Russian-related content.
| Sentiment | Positive | Negative |
|---|---|---|
| Russia | 9% | 40% |
| Ukraine | 15% | 36% |
TABLE 6 Positive/Negative Sentiments by Keywords. Visualization Code.
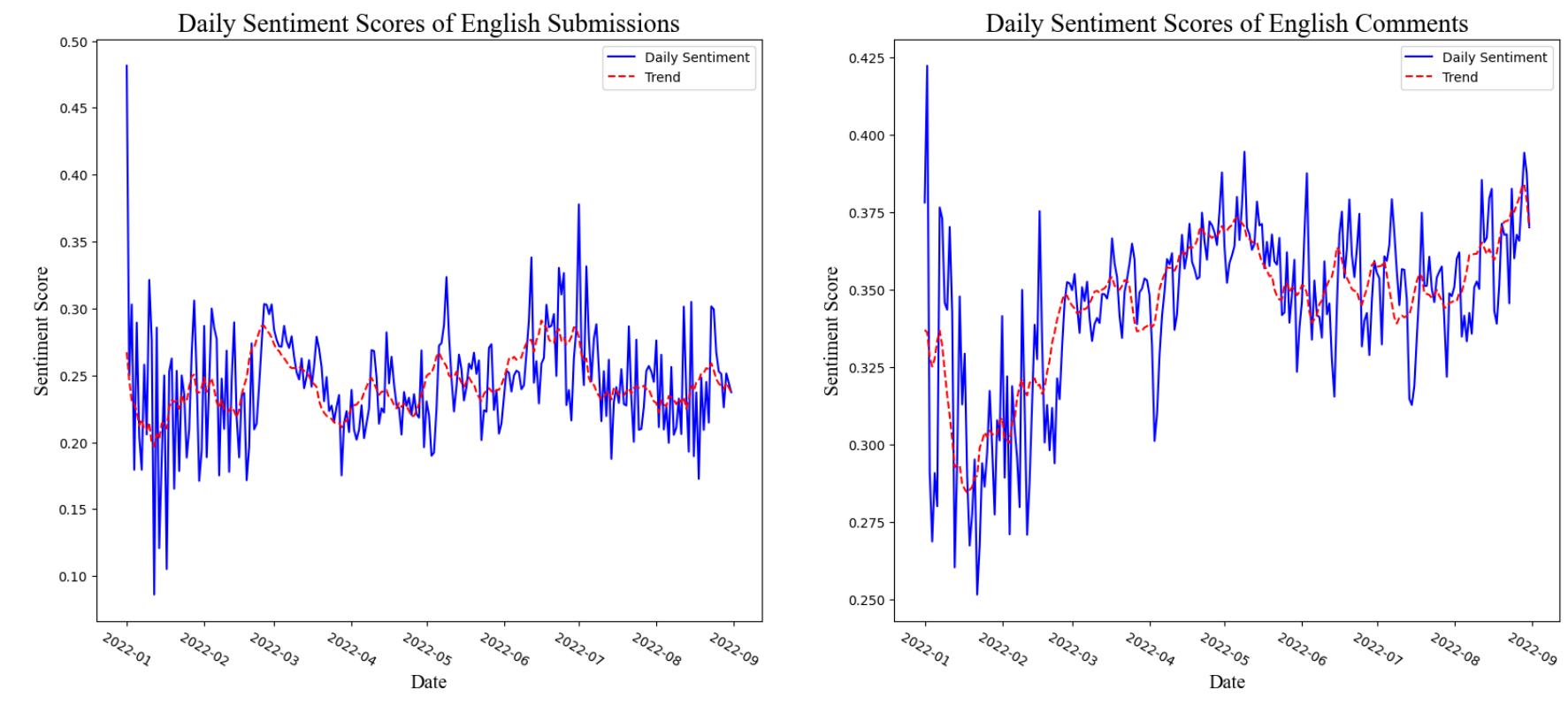
FIGURE 5 Sentiment Score Time Series. Trend is the 10-day moving average.Visualization Code.
Figure 5 plots the aggregated daily average sentiment scores for comments and submissions. Both charts had a steep upward trend at the end of February. Compared to submission sentiment score's stale trend, comment sentiment is getting more and more positive. We think it makes sense that comments are usually more emotional than submissions, especially at the beginning of the conflict. That's why we see a large dip at the beginning of the comment sentiment chart(right).
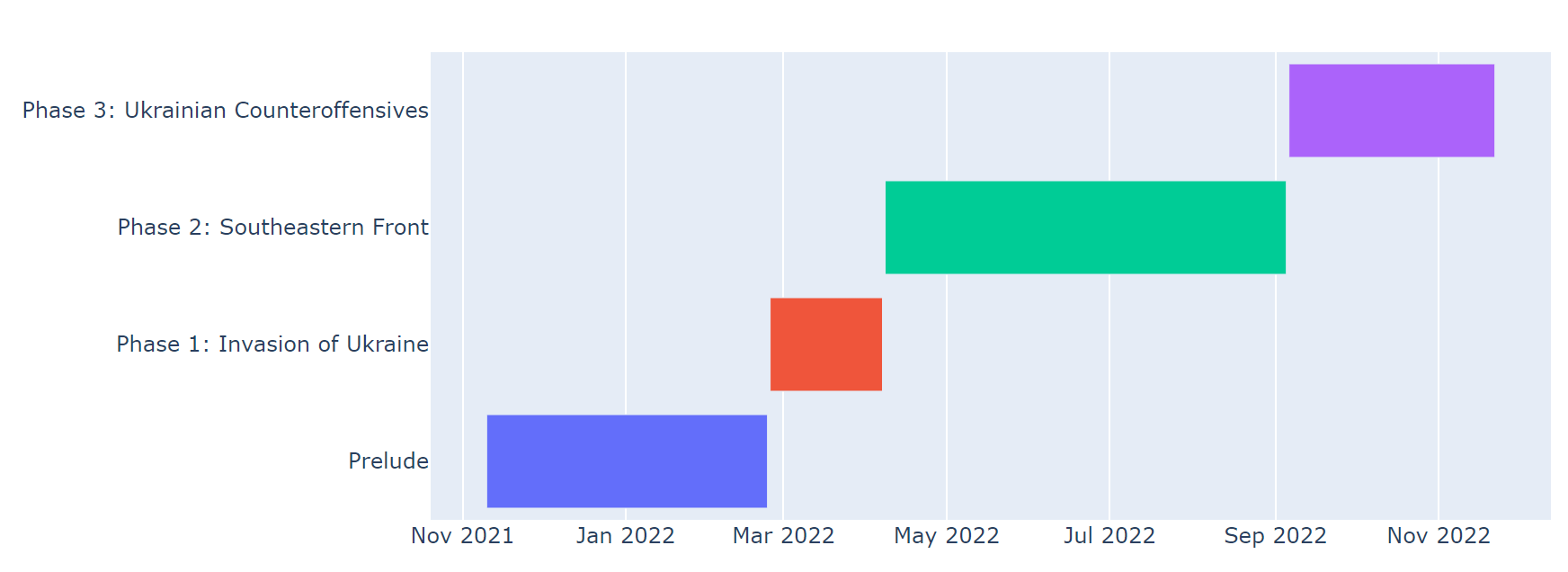
FIGURE 6 Russia-Ukraine Conflict Event Timeline.Visualization Code.
Figure 6 plots the event line of Russia-Ukraine Conflict.
In the Prelude phase, contradictions were fermented between Russia and Ukraine on many issues, among which the most significant one is whether Ukraine should enter NATO.
Once the prelude ended and the war began in the end of February, reddits on the RU topic exploded correspondingly, both for the positive ones and negative ones. A large number of submissions and comments on this topic were posted in a short time.
In phase 1, Invasion of Ukraine, Russia launched the military invasion of Ukraine. The daily average sentiment scores of submissions experienced a decreasing phase, which reflects the fermentation of negative emotions of anxiety, disorder and even panic. Meanwhile, the sentiment scores of comments fluctuated largely due to the uncertainties of the war.
In phase 2, Southeastern Front, the area of heavy fighting shifted to the south and east of Ukraine. The number of submissions decreased largely, which is the common case for most news topics. The sentiment scores of comments were fluctuating largely during this period, which reflects the emotion of the disturbed people who still paid close attention to the conflict.
In phase 3, Ukrainian Counteroffensives, Ukrainian forces retook substantial ground during counteroffensives in the south and east, continuing to the present day. The number of both positive and negative posted reddits became stabler than previous. Sentiment scores of comments started to increase in this phase. Most people no longer worried about the burst of the potential 'Third World War'.
Q6. Is there difference in the sentiments among different ages?
Our original plan was to explore the difference in sentiment between under_18 and over_18 Redditors. However, we decide not to move forward with this business question, since the “over_18” column in Reddit is highly unreliable. Upon our investigation, “over_18” turns out to be a default choice when signing up for a Reddit account, and it doesn't have any verification procedure. In our dataset, more than 90% of the Redditors are under 18 and we find it very unlikely.
Q8.(External Data) How does each topic correlate to the commodity price changes?
It is a common practice to use correlation as preliminary analysis to test simple relationships between variables. Figure 7 plots the Pearson correlations between all the timeseries we collected during the 8-month period.
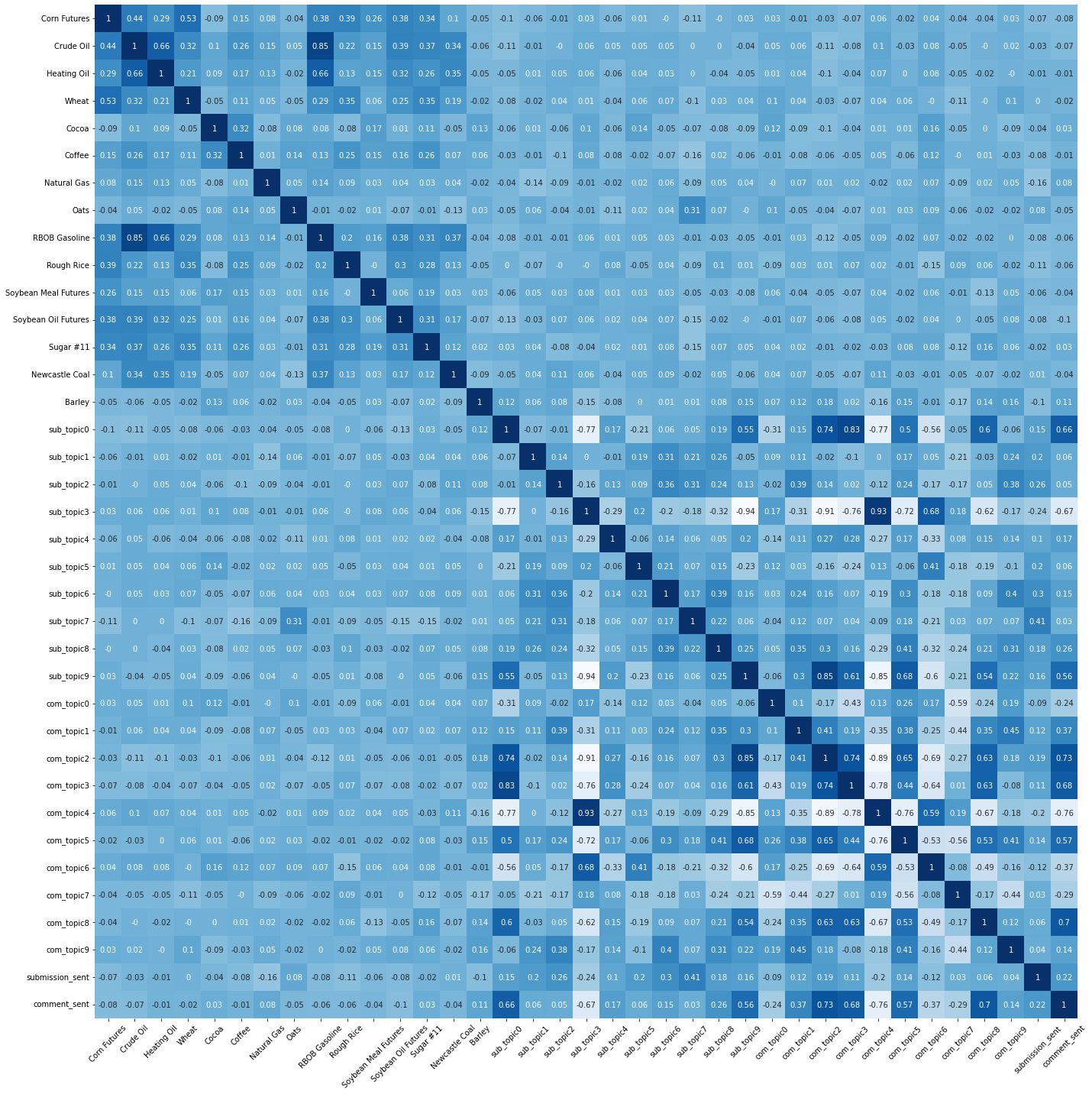
FIGURE 7 Correlations between topics, sentiments, and commodity returns.Visualization Code.
The highlighting areas concentrate on the top-left and bottom-right corners, indicating there is strong relationship within commodity returns and reddit textual features, but not between them. Since our goal is to use reddit to predict commodity returns, a weak correlation between predictor and target implies we will need better features and a better-than-linear model.